My research focuses on time series foundation models; covering synthetic data generation, causal intervention in hidden states, and improving forecasting robustness on real-world problems.
Choosing the wrong synthetic generator for time-series foundation model pretraining is costly: under identical training budgets, the best and worst generators produce up to a 2x gap in forecasting error, yet the field has no principled way to make this choice. The problem is compounded by the fact that generator rankings are not stable across architectures: across 11 generator families evaluated on Chronos-T5-Mini and Moirai-Small trained from scratch, we find that which generators are useful depends on the model architecture. Rather than solving the generator selection problem, we sidestep it: a simple equal-weight mixture of all generators matches or beats the best individual generator for both architectures, and composing this mixture with real data yields the strongest pretraining corpora overall. Synthetic pretraining is therefore a corpus composition problem, not a generator selection problem, and composition choices should be validated per model family rather than assumed to transfer.
@inproceedings{nagpal2026mixdontpicksynthetic,title={Mix, Don{\textquoteright}t Pick: Why Synthetic Corpus Composition Matters for Time Series Foundation Model Pretraining},author={Nagpal, Aaryan and Sanyal, Debdeep and Mandal, Murari and Kumar, Dhruv and Deshpande, Saurabh},booktitle={2nd ICML Workshop on Foundation Models for Structured Data},year={2026},note={Also accepted to the ICML 2026 Workshop on AI Forecasting},}
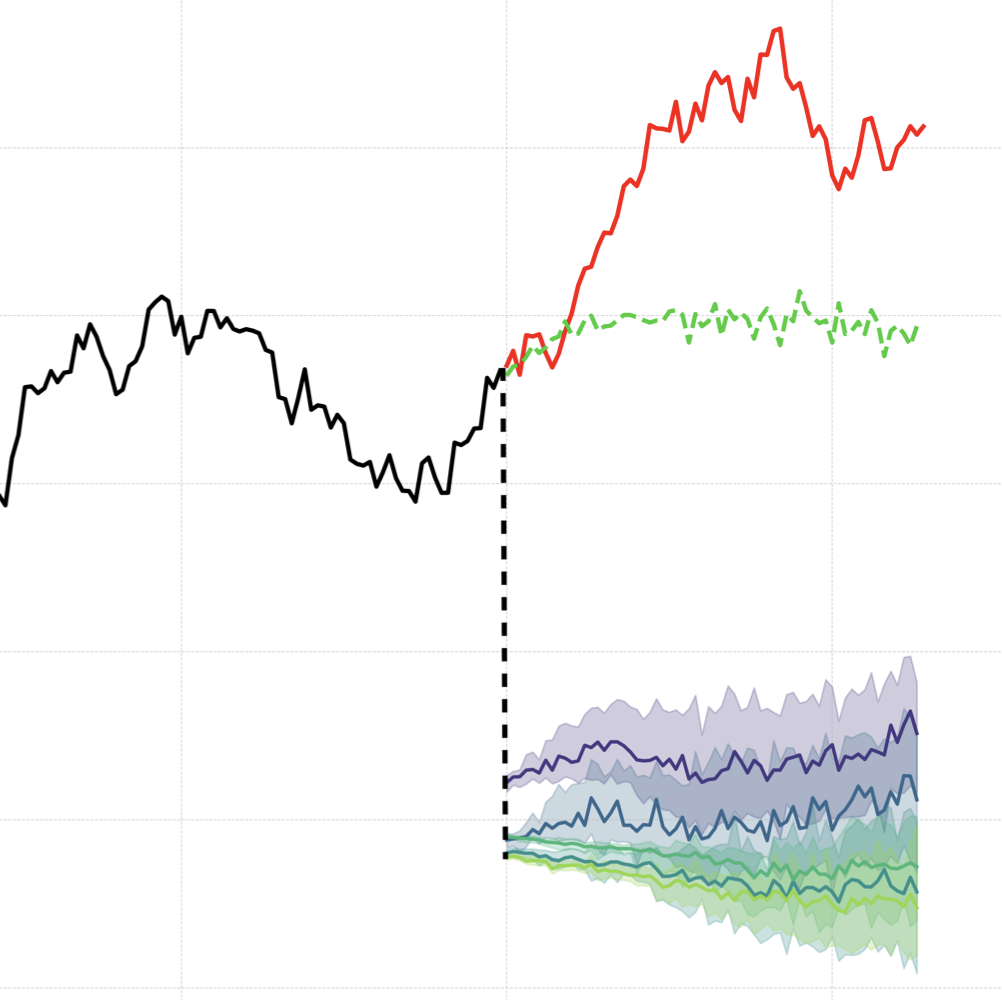
While transformer-based foundation models excel at forecasting routine patterns, two questions remain: do they internalize semantic concepts such as market regimes, or merely fit curves? And can their internal representations be leveraged to simulate rare, high-stakes events such as market crashes? To investigate this, we introduce activation transplantation, a causal intervention that manipulates hidden states by imposing the statistical moments of one event (e.g., a historical crash) onto another (e.g., a calm period) during the forward pass. This procedure deterministically steers forecasts: injecting crash semantics induces downturn predictions, while injecting calm semantics suppresses crashes and restores stability. Beyond binary control, we find that models encode a graded notion of event severity, with the latent vector norm directly correlating with the magnitude of systemic shocks. Validated across two architecturally distinct TSFMs, Toto (decoder only) and Chronos (encoder-decoder), our results demonstrate that steerable, semantically grounded representations are a robust property of large time series transformers. Our findings provide evidence for a latent concept space that governs model predictions, shifting interpretability from post-hoc attribution to direct causal intervention, and enabling semantic what-if analysis for strategic stress-testing.
@inproceedings{sanyal2025timetime,title={time2time: Causal Intervention in Hidden States to Simulate Rare Events in Time Series Foundation Models},author={Sanyal, Debdeep and Nagpal, Aaryan and Kumar, Dhruv and Mandal, Murari and Deshpande, Saurabh},booktitle={Recent Advances in Time Series Foundation Models Have We Reached the 'BERT Moment'?},year={2025},}